Chapter 1. NSCLDAQ In a Nut Shell
NSCLDAQ is a software suite that provides a flexible and extensible framework for handling the data flow produced by nuclear physics experiments. It aims to solve the top-level problem of managing the data stream by breaking it down into smaller problems solved by smaller applications. It therefore is a collection of tools that can be assembled into more complicated applications. This approach enables NSCLDAQ to be a modular system capable of tackling a wide range of experimental setups, from small calibration setups to merging multiple independent data acquisitions into unified systems.
1.1. Basics of Data Flow in NSCLDAQ
A major component of NSCLDAQ is the ability for it to manage data flows. A data flow is the path each element of data follows between the point of its originating process and destination process(es). The backbone of data flow in NSCLDAQ is the ring buffer. The ring buffer is the primary mechanism for making data available to different processes. The idea is that ring buffers are holding points for data. Processes can deposit data into them and others can read data out of them. More will be described on this in the next section. The ring buffer subsystem largely operates in the background and users do not deal too much with it besides specifying to processes where they should read data from or write data to.
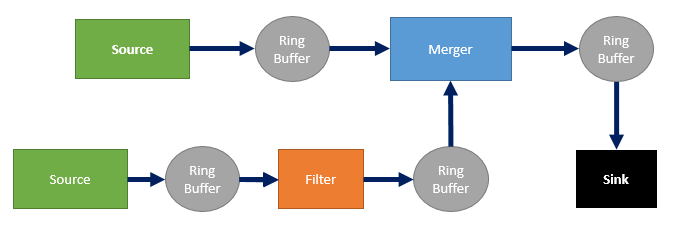
The programs that users deal with fall into a couple categories. Some operate in the data streams and others manage the entire system. Let's start with those that operate within the data stream. There are 4 different process types of this sort. The first is a data source. Data sources only output data. They do not read data from any upstream process. A good example of a data source is a Readout program. Readout programs interface with hardware and then output their data. It is most often the case that data sources output their data to a ring buffer. The next type of process is a data sink. Data sinks only read data from an input source (typically a ring buffer). There are many examples of data sinks. Two good examples are processes that write the data stream to a file and processes that help users inspect the data. Besides data sources and sinks, there are filter programs that have both an input and an output. Filters perform lots of tasks, two of which are transforming data between formats and inline data integrity checking. The final type is a merger process. It is characterized by having multiple inputs and a single output. There is only one example of such a program in NSCLDAQ, and that is the event builder. The way that we have used "data source" and "data sink" so far is in an absolute sense. They are a start or end of the data stream. We sometimes refer to sources and sink in a relative sense. The location a filter reads from is its source and the location it sends data to is its sink. Usually these refer more to passive entities like files or ring buffers. By tracing the path of data from process to process, we define a data flow.
It is useful to visualize the data flow for any given setup with a flow chart. Each piece of the chart is either a ring buffer, data source, data sink, merger, or filter. So that you have a sense for what NSCLDAQ builds for each experiment, here is a sample experimental setup diagrammed out.